# 状態管理
この章では、フロントエンドの状態管理について見ていきます。フロントエンドの状態は大きく分けて、次のようなものがあります。
- ローカル State
- グルーバル State
- APIのキャッシュ
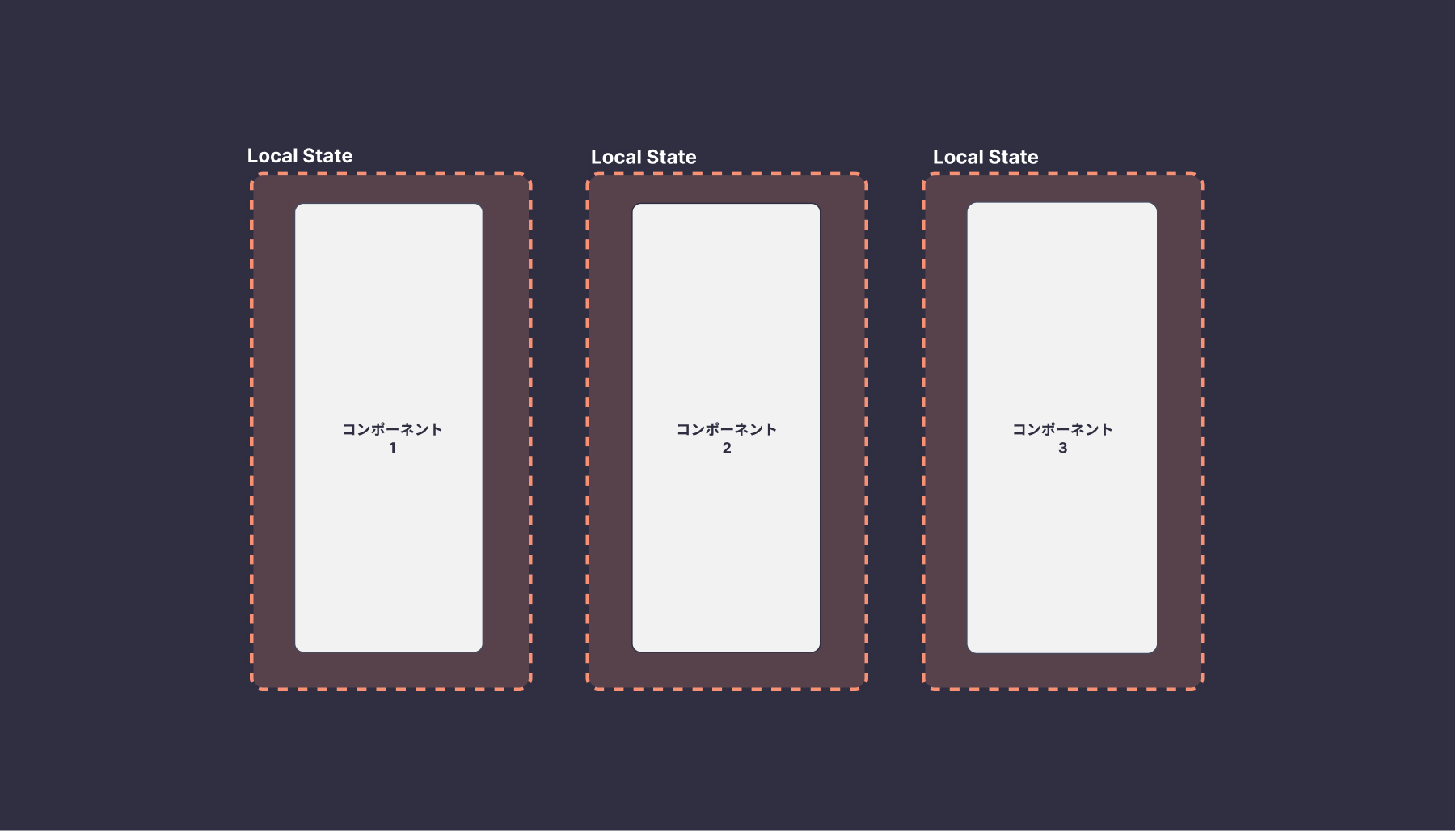
ローカル Stateは、コンポーネント内部で使われる状態で、useStateを使って管理します。コンポーネントのみ、あるいは、ページ内でのみ使われるデータを指します。
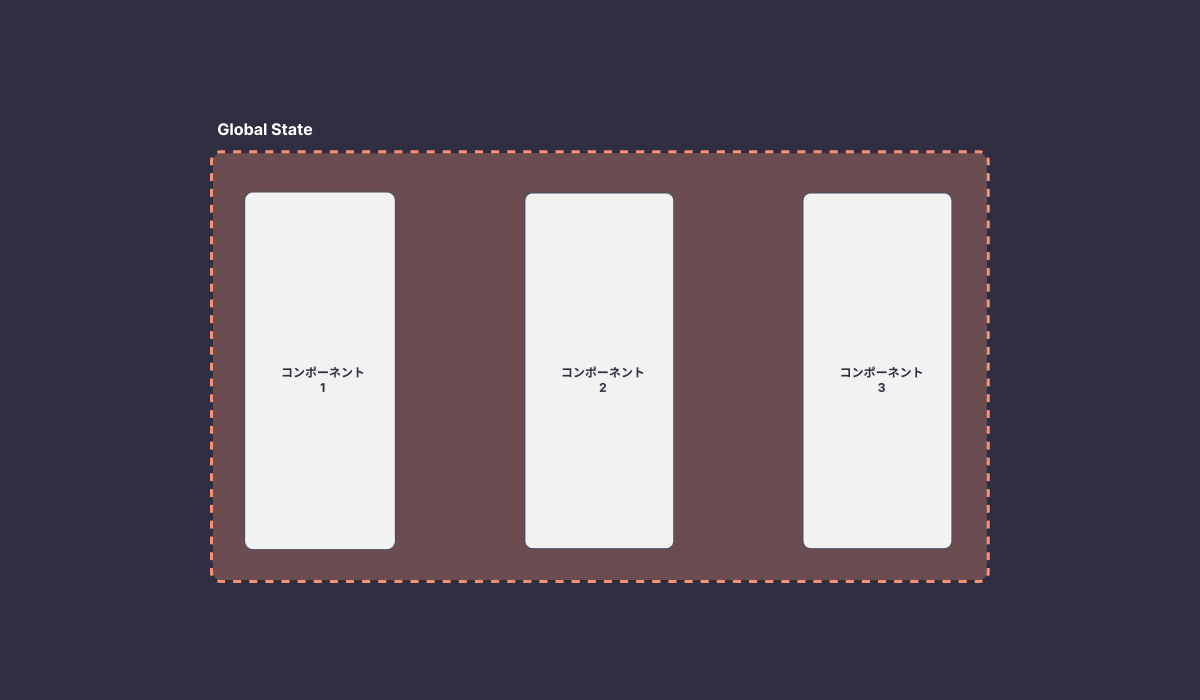
グローバル Stateはアプリケーション全体で参照される状態になります。例えば、アカウント情報や、認証情報などが含まれます。実装方法は、Redux、Recoil、Jotaiなどの状態管理ライブラリを使用するか、ReactのContext APIを使うことで実現できます。
APIのキャッシュは、SWRやApollo Clientといったクライアントライブラリで保持されるキャッシュになります。これらは、基本的にライブラリのキャッシュ機構を利用する形となるため、自前で実装することはありません。ただ、どのキャッシュ戦略を使うかは判断する必要があります。例えば、Apollo Clientのキャッシュは以下のようのキャッシュポリシー (opens new window)が提供されています。
- cache-first
- cache-only
- cache-and-network
- network-only
- no-cache
- standby
ページによって取得するデータの種類や要件は異なります。それぞれの要件に合わせて、キャッシュの選定が重要になります。
この章では、ローカル Stateとグローバル Stateの設計パターンについて見たいと思います。アプリケーションの要件によって、求められる状態管理は異なります。要件に合わせた最適な設計ができるように、いくつかのパターンを見てみましょう。
# Storeの分け方
Storeの設計は大きく分けて、垂直パターンと水平パターンの2種類あります。
# 垂直パターン
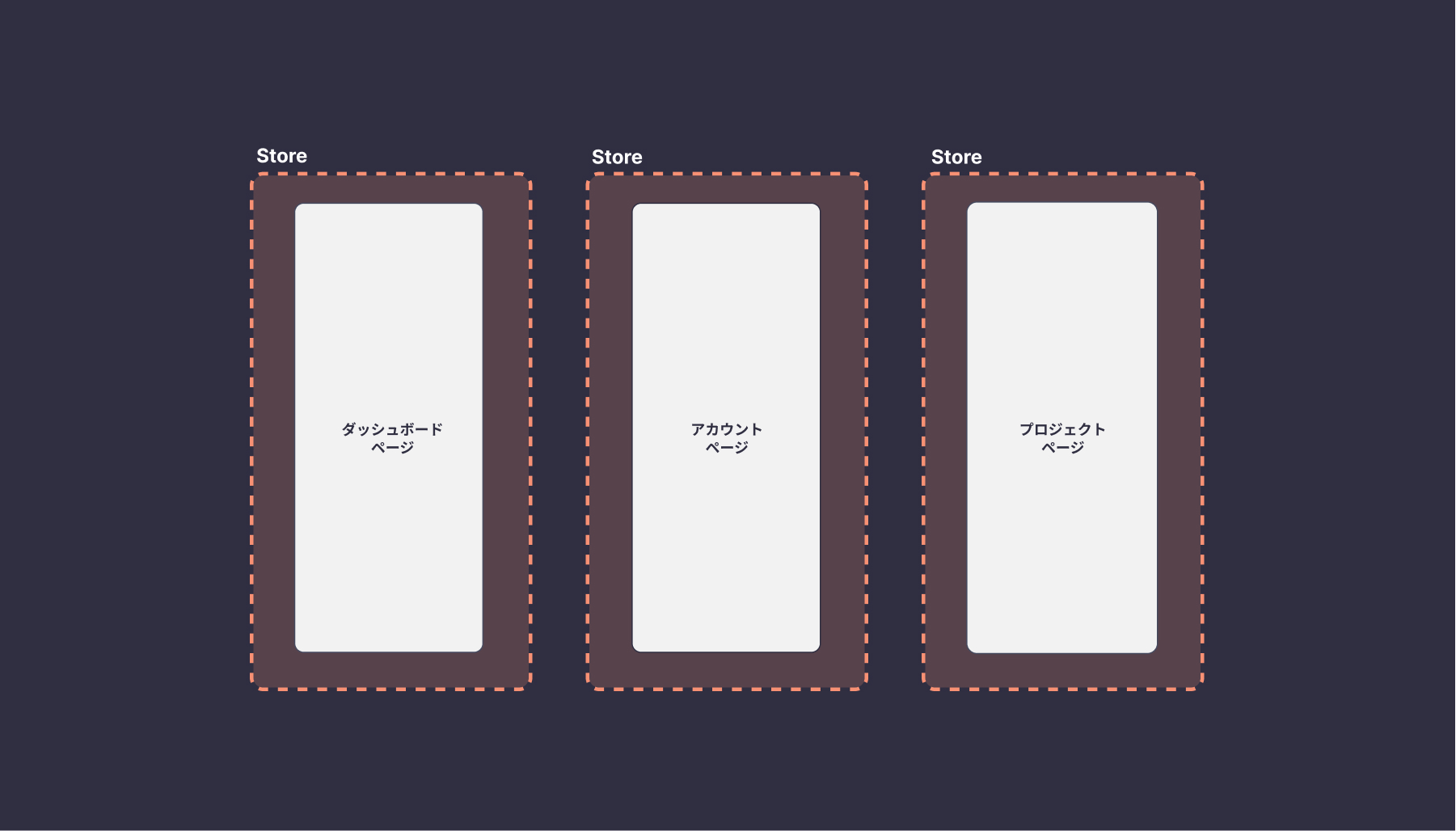
垂直パターンは、ページ単位で分割するパターンになります。ページごとに状態を持ち、他のページと状態を共有することはありません。そのため、状態の変更をしてもページ間で影響を与えることはありません。ローカル Stateをページ単位で区切って、グローバル Stateは別で管理します。
# 実装方法
実装方法は、次の二つが考えられます。
- コンポーネントから下層のコンポーネントへデータを渡す
- Storeをページ単位で定義する
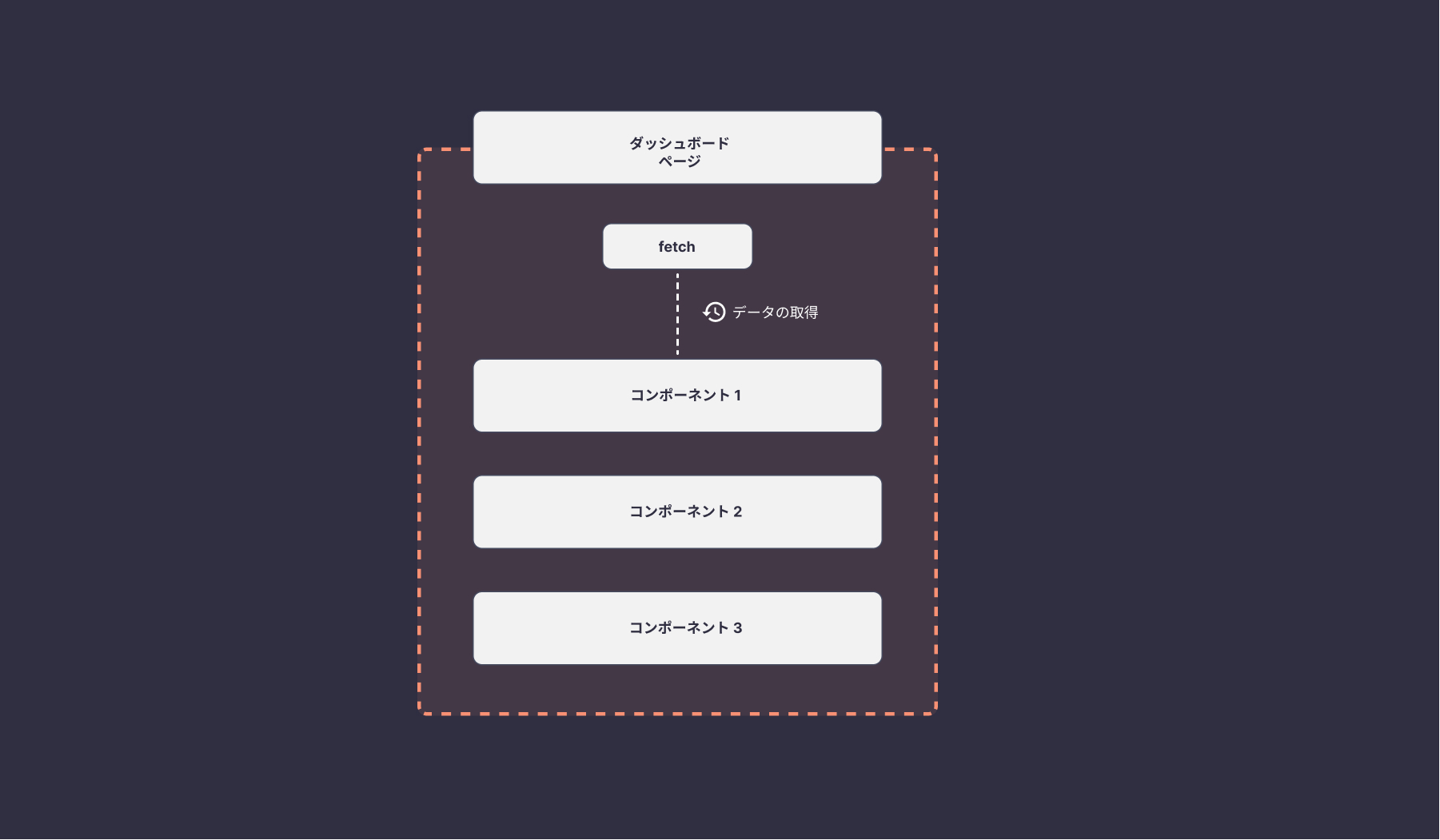
コンポーネントから下層のコンポーネントへデータを渡すパターンでは、一番トップのコンポーネントでAPIのデータを取得し、そのまま下層のコンポーネントへデータを渡します。データの渡し方は、Props経由で渡すかContext APIなどを使うことができます。
Storeをページ単位で定義するパターンは、ReduxやRecoilなどでStoreを定義し、ページ単位で管理します。コンポーネントで状態の管理はせず、Storeのデータを参照・更新してデータのやり取りをします。
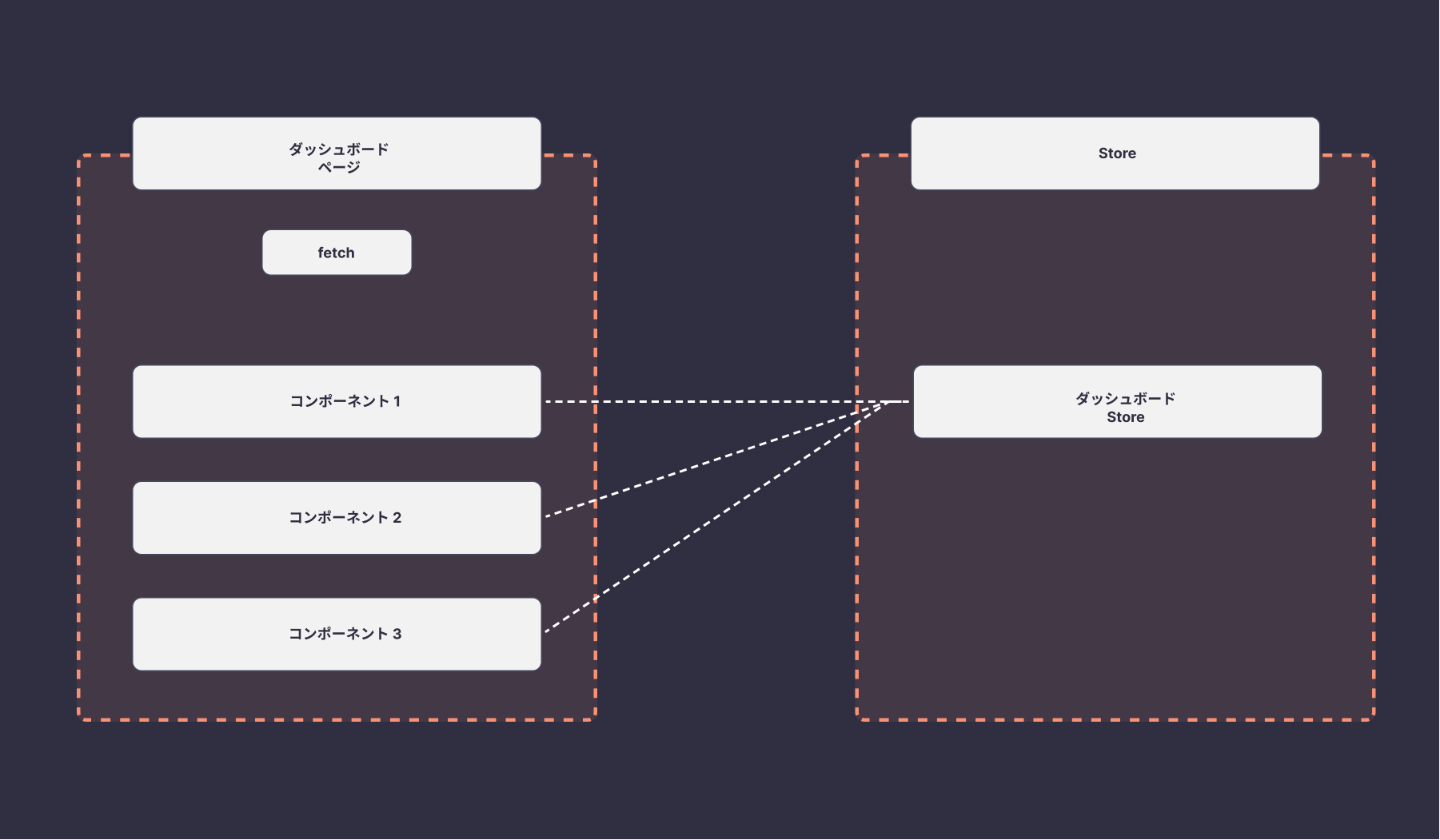
この場合、APIから取得したデータをStoreで管理し、FormやUIで使う状態をコンポーネント側で管理します。
TIP
MVVMパターンの文脈で言うと、APIから取得したデータやビジネスロジックに関わるデータをModelとし、FormやUIで使う状態をView Modelとします。
# メリット
垂直パターンのメリットは、ページ単位で状態管理ができるため、影響範囲を限定的にできることです。ページの外に状態が露出することがないため、データ構造を柔軟に変更することができます。また、コンポーネント間のデータのやり取りもProps経由、あるいはページ専用のStoreで行うため、コンポーネントの見通しが良くなります。
# デメリット
垂直パターンのデメリットは、複数のページやUIで状態を共有しづらいことです。例えば、モーダル内の状態と、ページ内の状態を同期させたい場合は、二つの状態を更新する必要があります。また、タブでページが独立している場合なども、同期する必要性があるでしょう。リアルタイムの更新性のあるシングルページアプリケーションの場合なども、複数のUIの更新が必要になるため、垂直パターンでは難しい傾向にあります。
# 適したアプリケーション
垂直パターンに適したアプリケーションは、リアルタイムの更新性を必要としないアプリケーションになります。具体的には、ECサイトやブログサイト、ページごとにフォームがあるCMSサイトなどが当てはまるでしょう。
# 水平パターン
水平パターンは、ドメインなどに状態を分割して、ページを横断して使うパターンになります。複数のページやUIで共通の状態を参照するため、データの一貫性を保つことができます。基本的に全ての状態は、どのコンポーネントからでもアクセスできるため、グローバル Stateのように振る舞います。
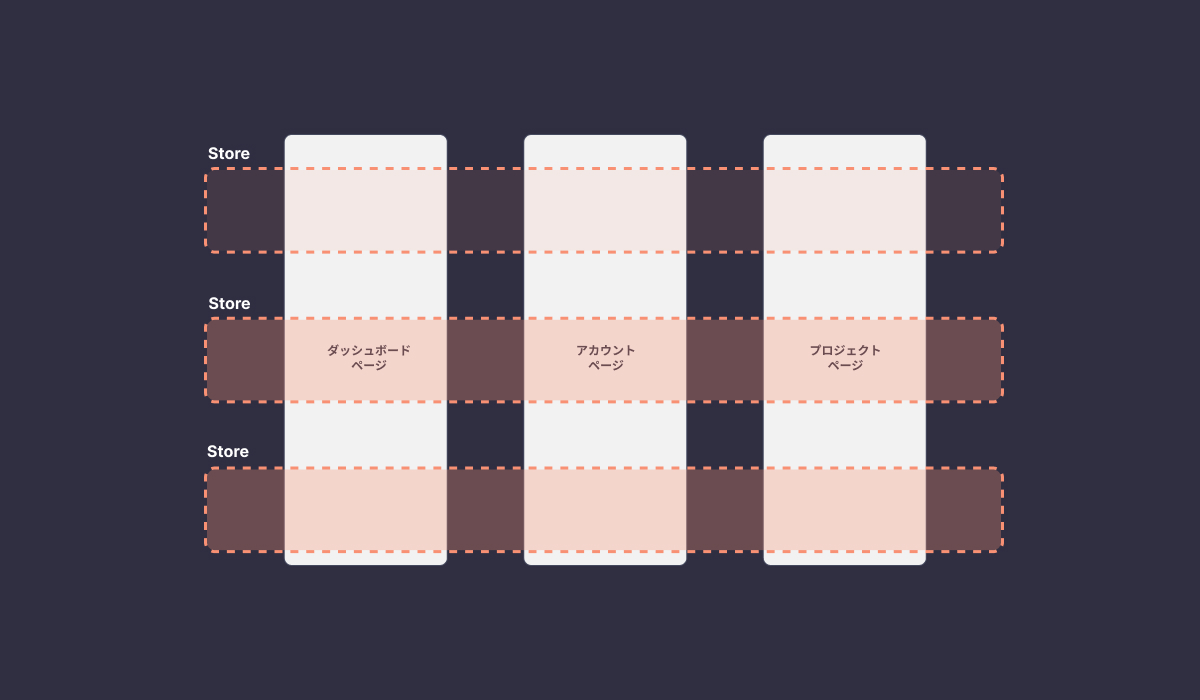
# 実装方法
水平パターンの実装は、ReduxやRecoilなどの状態管理ライブラリを使って、ドメインごとに設計します。例えば、タスク管理ツールのようなアプリケーションの場合、Tasks、Users、Projects、Workspacesなどの単位で分けることができるでしょう。それぞれの状態をドメインごとに分けた場合、次のような構成にすることができます。
src/store/
├── project
├── projectIcon
├── projectTask
├── projectTeammate
├── tag
├── task
├── taskCollaborator
├── taskFeed
├── taskFeedLike
├── taskFile
├── taskLike
├── taskPriority
├── taskTag
├── teammate
├── teammateTask
├── workspace
└── workspaceTeammate
さらに、状態の正規化 (opens new window)をすることで、状態同士の関連性を紐づけることができます。状態の正規化については、後ほど詳しく見たいと思います。
# メリット
水平パターンのメリットは、複数のUIで状態の一貫性を保ちやすいことです。全てのUIが同じ状態を参照するので、データの更新が一回で済みます。そのため、更新性の高いシングルページアプリケーションなどに向いています。
# デメリット
水平パターンのデメリットは、影響範囲が特定しづらいことです。全てのUIで共有されるということは、その分影響範囲が広がってしまいます。変更をした箇所については、参照している全てのUIのチェックが必要になります。ただし、データの整合性についてはTypeScriptの型チェックで防ぐことができます。また、Visual Regression Testingsで、UIのチェックも可能でしょう。
垂直パターンはページごとに状態を設計するのに対し、水平パターンはドメインごとに設計するため、ドメイン知識が必要になります。そのため、設計コストが高くなる傾向があります。
# 適したアプリケーション
水平パターンに適したアプリケーションは、更新性の高いアプリケーションになります。例えば、入力した瞬間にシームレスにデータが更新されるようなシングルページアプリケーションが当てはまるでしょう。ダッシュボードツールやプロジェクト管理ツールなど、複雑なUIで構成され、かつ更新性の高いアプリケーションの場合、水平パターンが有効になります。
# 正規化(Normalized State)
正規化 (opens new window)とは、リレーショナルデータベースのように一つ一つのデータに対してIDを付与して、テーブルのように状態を設計するパターンです。それぞれデータは、IDを通して参照する仕組みになります。例えば、次のようなブログのデータがあるとしましょう。
export const posts: Post[] = [
{
id: 'post1',
author: { username: 'user1', name: 'User 1' },
body: '記事本文....',
comments: [
{
id: 'comment1',
author: { username: 'user2', name: 'User 2' },
comment: 'コメント'
},
{
id: 'comment2',
author: { username: 'user3', name: 'User 3' },
comment: 'コメント'
}
]
},
{
id: 'post2',
author: { username: 'user2', name: 'User 2' },
body: '記事本文....',
comments: [
{
id: 'comment3',
author: { username: 'user3', name: 'User 3' },
comment: 'コメント'
},
{
id: 'comment4',
author: { username: 'user1', name: 'User 1' },
comment: 'コメント'
},
{
id: 'comment5',
author: { username: 'user3', name: 'User 3' },
comment: 'コメント'
}
]
}
]
postsの配列の中に、authorの情報があり、commentsの中にもauthorが含まれています。authorの情報が重複している箇所がいくつかあるのが分かります。
export const posts: Post[] = [
{
id: 'post1',
author: { username: 'user1', name: 'User 1' },
body: '記事本文....',
comments: [
{
id: 'comment1',
author: { username: 'user2', name: 'User 2' },
comment: 'コメント'
},
{
id: 'comment2',
author: { username: 'user3', name: 'User 3' },
comment: 'コメント'
}
]
},
{
id: 'post2',
author: { username: 'user2', name: 'User 2' },
body: '記事本文....',
comments: [
{
id: 'comment3',
author: { username: 'user3', name: 'User 3' },
comment: 'コメント'
},
{
id: 'comment4',
author: { username: 'user1', name: 'User 1' },
comment: 'コメント'
},
{
id: 'comment5',
author: { username: 'user3', name: 'User 3' },
comment: 'コメント'
}
]
}
]
このような重複したデータを更新する場合、全ての配列から該当のデータを検索する必要があります。また、ネストした配列がある場合は、さらに複雑な検索になる可能性があります。ネストされたデータを更新するたびに、リスト全体を更新する必要も発生するでしょう。例えば、次のようなコメントのLikeボタンを押下した場合、ネストしたデータを更新する必要があるため、関係のないところまでレンダリングが発生してしまいます。
TIP
React Developer ToolsのHighlight updates when components render.にチェックを入れると、レンダリングを可視化できます。
パフォーマンスを高めるなら、Likeボタンに紐づいたコメントのみレンダリングされることが求められます。Reactでは、Context APIを使うことで実現可能ですが、正規化でも同様のことができます。前述したデータを正規化した場合、次のような構造になります。
{
posts : {
byId : {
"post1" : {
id : "post1",
author : "user1",
body : "......",
comments : ["comment1", "comment2"]
},
"post2" : {
id : "post2",
author : "user2",
body : "......",
comments : ["comment3", "comment4", "comment5"]
}
},
allIds : ["post1", "post2"]
},
comments : {
byId : {
"comment1" : {
id : "comment1",
author : "user2",
comment : ".....",
},
"comment2" : {
id : "comment2",
author : "user3",
comment : ".....",
},
"comment3" : {
id : "comment3",
author : "user3",
comment : ".....",
},
"comment4" : {
id : "comment4",
author : "user1",
comment : ".....",
},
"comment5" : {
id : "comment5",
author : "user3",
comment : ".....",
},
},
allIds : ["comment1", "comment2", "comment3", "comment4", "comment5"]
},
users : {
byId : {
"user1" : {
username : "user1",
name : "User 1",
},
"user2" : {
username : "user2",
name : "User 2",
},
"user3" : {
username : "user3",
name : "User 3",
}
},
allIds : ["user1", "user2", "user3"]
}
}
posts、comments、usersでテーブルのように分割します。それぞれのデータにはユニークのIDを付与します。関連するデータがある場合は、そのIDを保持します。例えば、commentsはusersのIDを持ちます。
"comment1" : {
id : "comment1",
author : "user2",
comment : ".....",
},
このような構造にすることで、ネストされたデータをフラットな状態にできます。一意のデータ構造になるため、複数のオブジェクトを更新する必要はありません。また、それぞれのデータをIDで参照することができるため、複雑な検索をする必要もありません。リレーショナルデータベースのようなテーブル関係をイメージすると分かりやすいでしょう。
例えば、Reactでリストを実装する場合、親のコンポーネントでIDの配列を取得します。そして、子供のコンポーネントでそのIDをもとにデータを取得することができます。
親のコンポーネント:
function Parent() {
const { ids } = usePostIds()
return (
<>
{/* IDだけを渡す */}
{ids.map(id => (
<Child key={id} id={id} />
))}
</>
)
}
子供コンポーネント:
function Child({ id }) {
// IDをもとにデータを参照する
const { post } = usePost(id)
return (
<>
<div>{post.name}</div>
</>
)
}
また、更新する場合は、子供コンポーネントで直接実行することができます。
function Child({ id }) {
const { post, setPost } = usePost(id)
// 子供コンポーネントで直接データを更新する
const handleClick = () => {
setPost({ ... })
}
return (
<>
<div>{post.name}</div>
<button onclick={handleClick}>更新する</button>
</>
)
}
このように子供のコンポーネントでデータを参照・更新することで、無駄な再レンダリングを防ぐことができます。なぜなら、親のコンポーネントで取得しているIDの配列が変わらない限り親コンポーネントはレンダリングされないからです。親コンポーネントがレンダリングされなければ、子供コンポーネント全体がレンダリングされることはありません。そのため、更新があった子供コンポーネントのみレンダリングされることになります。正規化することによって、このようにレンダリングパフォーマンスの最適化をすることができます。
# 実装方法
では、実際に正規化の実装方法を見てみましょう。今回は、Recoil (opens new window)を使ってStoreを設計します。
次のような、記事一覧とコメントが表示されるアプリケーションを想定してみましょう。
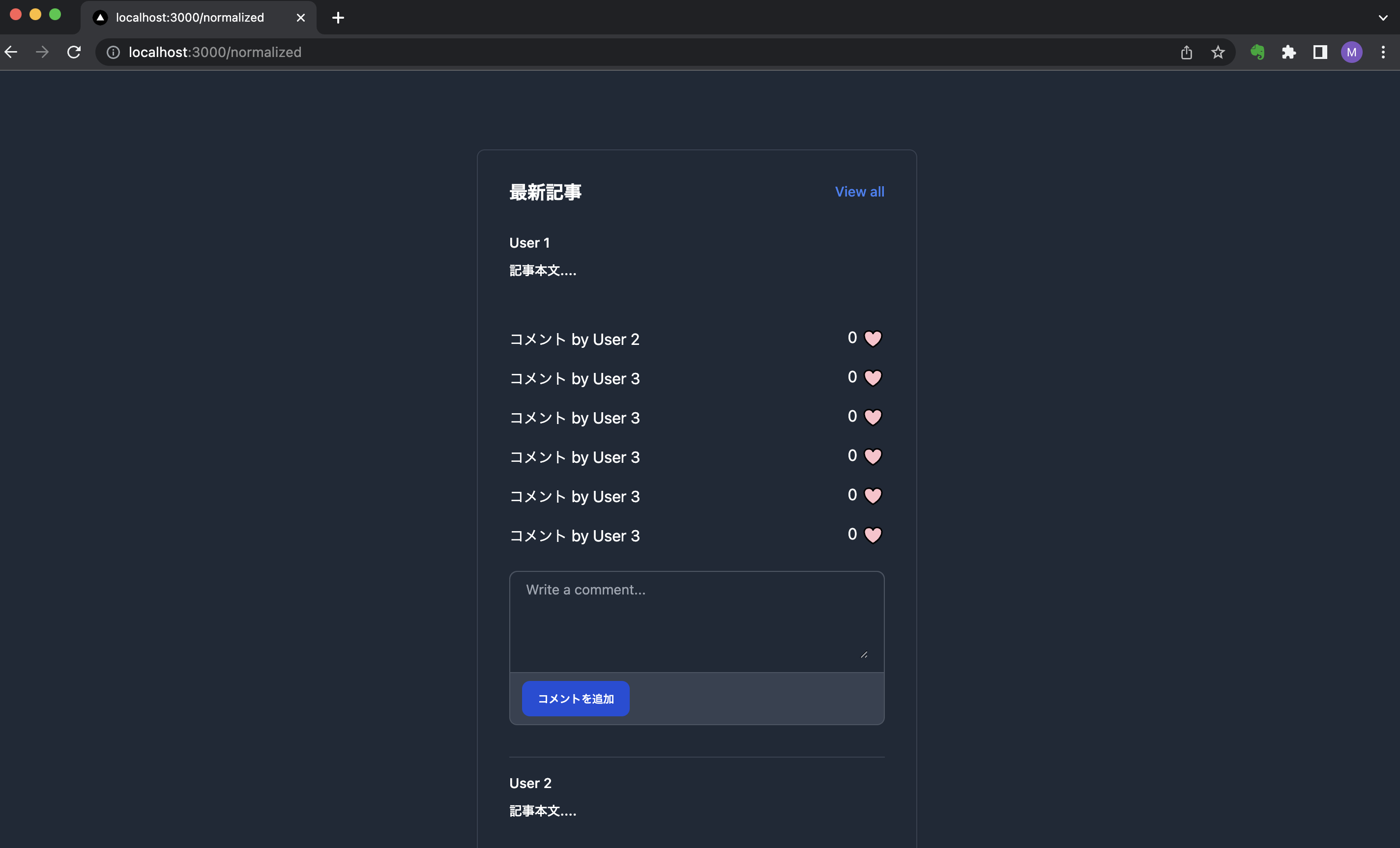
まず、はじめにStoreを設計します。Storeの構成は以下の通りです。
src/store
├── comment
├── commentLike
├── post
├── user
└── util
postが記事一覧で、commentがコメント一覧、commentLikeはコメントのお気に入り数、 userはコメントするユーザーや著者を表します。簡略化のため、コメントのお気に入り数はユーザーごとではなく、押下されるたび増加するものとします。
それぞれの構成は次のようになっています。
src/store/post
├── atom.ts
├── hooks
│ ├── index.ts
│ ├── usePost.ts
│ └── usePostIds.ts
├── index.ts
└── type.ts
atoms.tsはRecoilのatomsを定義しています。hooksはそのatomsを参照してデータを取得し、コンポーネントと繋げるためのHooksを定義しています。
まずは、atoms.tsを見てみましょう。
import { createState } from '../util'
import { Post } from './type'
const key = (str: string) => `src/store/post/${str}`
export const initialState = (): Post => ({
id: '',
authorId: '',
body: '',
})
export const {
state: postState,
listState: postsState,
idsState: postIdsState,
} = createState({ key, initialState })
createStateという汎用的な関数を通して、atomsを生成しています。postStateは記事単体で使うためのState、postsStateは記事一覧のState、postIdsStateは記事一覧のIDのStateになります。これらを使ってHooksを作成します。
TIP
createStateの実装は以下になります。Recoilの基礎知識が必要になるため詳しくは解説しませんが、ここでは単体のStateと一覧のStateの整合性を保つように設計してあります。
import { atom, atomFamily, DefaultValue, selectorFamily } from 'recoil'
import { uniqBy } from '@/shared/utils/uniqBy'
type Props<T> = {
key: (str: string) => string
initialState: () => T
set?: (params: { newVal: T }) => void
}
type State = {
id: string
}
export const createState = <T extends State>(props: Props<T>) => {
const atomState = atomFamily<T, string>({
key: props.key('atomState'),
default: props.initialState(),
})
const listState = atom<T[]>({
key: props.key('listState'),
default: [],
})
const idsState = atom<string[]>({
key: props.key('idsState'),
default: [],
})
const state = selectorFamily<T, string>({
key: props.key('state'),
get:
(id) =>
({ get }) =>
get(atomState(id)),
set:
(id) =>
({ get, set, reset }, newVal) => {
// 一覧から削除されたらリセットする
if (newVal instanceof DefaultValue) {
reset(atomState(id))
set(listState, (prev) => {
return prev.filter((p) => p.id !== id)
})
set(idsState, (prev) => prev.filter((prevId) => prevId !== id))
return
}
// 単体のStateの更新
set(atomState(id), newVal)
// 一覧のStateの更新
set(listState, (prev) =>
uniqBy([...prev, newVal], 'id').map((p) =>
p.id === newVal.id ? { ...p, ...newVal } : p,
),
)
// ID一覧の更新
if (get(idsState).find((projectId) => projectId === newVal.id)) return
set(idsState, (prev) => [...prev, newVal.id])
props.set?.({ newVal })
},
})
return {
state,
listState,
idsState,
}
}
例えば、単体のStateが更新されたらリストの方も更新したり、リストからStateが削除されたら、単体のStateもリセットするなどの処理をしています。
Hooksは、単体の記事を参照するためのusePost.tsと記事一覧のIDを参照するusePodtIds.tsを定義します。
// usePost.ts
import { useRecoilValue } from 'recoil'
import { postState } from '../atom'
export const usePost = (postId: string) => {
const post = useRecoilValue(postState(postId))
return {
post, // { id: '1', authorId: '1', body: '...' }
}
}
// usePodtIds.ts
import { useRecoilValue } from 'recoil'
import { postIdsState } from '../atom'
export const usePostIds = () => {
const postIds = useRecoilValue(postIdsState)
return {
postIds, // [1, 2, 3]
}
}
このHooksをコンポーネントで使用して、データのやり取りをします。例えば、記事一覧を表示するコンポーネントでは、次のように記事一覧IDを取得します。
import { usePostIds } from '@/store/post';
export function Home() {
// IDを取得
const { postIds } = usePostIds()
return (
<div>
<div>
...
<div className="flow-root">
<ul role="list" className="divide-y divide-gray-200 dark:divide-gray-700">
{postIds.map(id => (
<ListItem
key={id}
postId={id}
/>
))}
</ul>
</div>
</div>
</div>
)
}
<ListItem postId={id}>コンポーネントでは、渡された記事IDをもとに、記事のデータを参照します。
import { Comments } from './Comments'
import { usePost } from '@/store/post';
import { useUser } from '@/store/user';
type Props = {
postId: string
}
export function ListItem(props: Props) {
const { postId } = props
const { post } = usePost(postId) // 記事IDをもとに記事データを取得する
const { user } = useUser(post.authorId) // authorIdをもとにユーザデータを取得する
return (
<li className="..." key={post.id}>
<div className="...">
<div className="...">
<p className="...">
{user.name}
</p>
<p className="...">
{post.body}
</p>
</div>
</div>
<div>
<Comments postId={postId} />
</div>
...
</li>
)
}
同様に、<Comments postId={postId} />では、記事IDをもとに関連したコメントIDを取得してレンダリングします。
import { Comment } from './Comment'
import { useCommentIdsByPostId } from '@/store/comment';
type Props = {
postId: string
}
export function Comments(props: Props) {
// 記事IDに紐づいたコメントのIDを取得する
const { commentIds } = useCommentIdsByPostId(props.postId)
return (
<div>
{commentIds.map(id => (
<Comment key={id} commentId={id} />
))}
</div>
)
}
<Comment commentId={id} />コンポーネントでは、コメントIDをもとにコメントデータを取得します。
import React, {useCallback} from 'react';
import { useComment } from '@/store/comment';
import { useUser } from '@/store/user';
import { LikeIcon } from './LikeIcon';
import { useCommentLikeCommand, useCommentLikesByCommentId } from '@/store/commentLike';
import { v4 as uuidv4 } from 'uuid';
type Props = {
commentId: string
}
function Comment(props: Props) {
const { commentId } = props
const { comment } = useComment(commentId) // コメントIDをもとにコメントデータを取得
const { user } = useUser(comment.authorId) // authorIdをもとにユーザデータを取得
const { setLikes } = useCommentLikeCommand()
const { commentLike } = useCommentLikesByCommentId(commentId) // コメントIDをもとにコメントのお気に入り数を取得
// お気に入りの更新
const handleLikes = useCallback(async () => {
await setLikes({
id: commentLike?.id || uuidv4(),
commentId
})
}, [commentId, commentLike?.id, setLikes])
return (
<div>
<p key={comment.id}>
{comment.comment} by {user.name}
</p>
<div>
<p>{commentLike?.likes ?? 0}</p>
<LikeIcon width={24} height={24} onClick={handleLikes} />
</div>
</div>
)
}
このように正規化されたStoreでは、IDを通してデータを参照することができます。各コンポーネントにはIDしか渡していないので、データの更新があったとしてもレンダリングを局所化することができます。例えば、正規化していない状態だと、データをまるごとコンポーネントに渡す必要があるため、コンポーネント全体がレンダリングされてしまいます。
しかし、正規化されていると、それぞれのコンポーネントでデータの更新をすることができるため、レンダリングを最小限に抑えることができます。
上記の例では、Likeボタンを押下したときに該当の<Comment />コンポーネントのみがレンダリングされています。コンポーネント全体がレンダリングされることはありませんし、他のコメントがレンダリングされることもありません。そのため、無駄な再レンダリングを防ぐことができます。
# メリット
正規化のメリットは、複数のUIに対して一貫性のあるデータを提供できることです。更新対象のStateが一箇所だけになるので、共通のHooksやAPIを共有することができます。更新頻度が高いアプリケーションの場合、正規化のメリットを享受しやすいでしょう。また、上述したように、レンダリングパフォーマンスの最適化をすることができます。複雑なUIでコンポーネントのネストが深くても、IDによるデータの参照や更新をすることで、パフォーマンスを向上させることができます。
# デメリット
正規化のデメリットは、Storeの設計コストが高くなることです。ドメインごとに分ける場合、どのぐらいの粒度で分けるべきかなど考慮する必要があります。また、APIからのデータを正規化のフォーマットに変更する必要があります。normalizr (opens new window)などのツールで自動変換することも可能ですが、APIのデータをそのまま使う場合と比べると、考慮するポイントが多くなります。