# フロントエンドの設計
この章では、フロントエンドの設計パターンについて見ていきたいと思います。具体的には、プロジェクトの構成、コンポーネントの設計、状態管理、テストの設計、CSSの設計などを紹介します。近年、Next.jsなどのフレームワークの進化によって、開発の効率が大幅に向上しました。SSRやISRといったレンダリング基盤や、パフォーマンスの最適化が標準でサポートされているため、開発者がアプリケーション開発に注力しやすい環境になっています。
しかし、依然として、コンポーネントの設計や状態管理の設計などが求められることに変わりはありません。 フロントエンドの周辺技術は、移り変わりが激しく、大規模なリファクタリングが必要な場面は多々あります。また、効率的な開発をするために、フレームワークのバージョンアップや、ライブラリの更新、新しい技術への変換などが求められることも多いです。バグの改修のためにライブラリの乗り換えをすることもあるでしょう。
また、ビジネスの要件にもいち早く対応することが求められます。機能要件を満たすために、新しいライブラリや技術を導入したり、既存のコンポーネントを大幅に変えることもあります。それ以外にも、パフォーマンスの最適化のために、大規模なリファクタリングが実施されることもあるでしょう。
このような変化に対応するためには、変更に強く柔軟な設計にする必要があります。フレームワークの使い方や新しい技術のキャッチアップも大切ですが、フロントエンドエンジニアに求められるスキルは、それらを使って安定的に開発するための設計力です。変更に強い土台を設計することで、機能追加やリファクタリングがしやすくなり、開発スピードが向上します。開発効率が良くなると、サービスの開発により注力することができるようになります。
この章では、フロントエンドに必要な設計パターンを学ぶことで、変更に強い土台を作ることを目指します。Reactをベースに検証しますが、他のフレームワークでも応用可能です。全ての設計パターンを適用する必要はありません。一つ一つのパターンを知ることで、有効になりそうなものを自身のプロジェクトに応用してみましょう。
システムを設計するための判断力は、知識をインプットするだけではなかなか身につきません。多くのプロジェクトを経験することで、覚えるものです。一番効率的なのは、自分で設計したプロジェクトを長い間運用することです。長期間運用することで、最初に設計した「ダメだった部分」が見えてきます。機能追加を優先し過ぎてコードの品質が低い、または、共通化し過ぎたり、レイヤーを分け過ぎたり、オーバーエンジニアリングして逆に複雑さが増してしまった、などのケースもあるでしょう。そういった「ダメだった部分」を修正したり、リファクタリングする過程で、メンテナンスしやすい設計を身につけることができます。
ただ、企業で複数のプロジェクトを設計できる機会は少ないと思います。おすすめは、個人開発で中規模程度のアプリケーションを開発することです。一人で設計から運用をすることで、設計のノウハウを身につけることができます。個人開発だからと言って、手を抜くのではなく、本番運用でも通用する設計を心がけてみましょう。
フロントエンドの設計で重要なことは、シンプルさを保つことです。シンプルさを保つとは、使用するフレームワークの仕様や思想を理解し、純粋さを保つことです。例えば、Reactでは宣言的にUIを構築し、コンポーネントは純粋な関数 (opens new window)であることが望まれます。純粋な関数とは、同じinputに対して、同じoutputを出力するという冪等性を維持することです。そのため、意図しない変更をもたらす副作用は排除することが求められます。また、コンポーネントは単一責任の原則で責務を明確にし、シンプルに保つこと、他の処理に影響を与えないことが必要になります。このような思想 (opens new window)を理解することで、適切な粒度でコンポーネントを設計することができます。
最初からいきなりクリーンアーキテクチャを導入するとかではなく、まずはシンプルに設計することから始めて、必要になってはじめて検討するのが建設的でしょう。そのためにも、変更に強い土台を作っておくのが重要になります。
# 変更に強い設計とは
継続的な進化をするために、フロントエンド開発に求められることは変更に強い設計です。変更に強い設計とは、変更を検知する仕組みと変更がしやすい仕組みを指します。変更がしやすい仕組みが整っていると、仕様変更やライブラリのバージョンアップに対応しやすくなります。また、変更を検知できる仕組みを整えておくことで、意図しない変更を検知し、リグレッションバグなどを防ぐことができます。大規模なリファクタリングの際の心理的負荷も軽減されるでしょう。これらを実現するために、具体的には、コンポーネントの再利用、テストの担保や、TypeScriptによる型検知、エラー検知が有効的です。一つずつ見てみましょう。
# コンポーネントの再利用
昨今のフロントエンド開発では、コンポーネント指向で開発することがほとんどです。コンポーネント指向では、適切な粒度でコンポーネントを設計することが重要です。フロントエンド開発でよく発生する課題は、コンポーネントが肥大化し過ぎてメンテナンスが困難になることでしょう。コンポーネントの再利用性を高めることで、肥大化の問題は解決することができます。
コンポーネントの再利用性を高めるためには、適切にコンポーネントを設計することです。例えば、Atomic Design (opens new window)などのデザイン手法を使うことでコンポーネントの粒度を設定することができます。

出典: Atomic Design (opens new window)
Atomic Designは、コンポーネントを適切な粒度に分けて管理しやすくするためのデザイン手法です。Atoms、Molecules、Organisms、Templates、Pagesでコンポーネントを分類し、小さなコンポーネントを組み合わせてアプリケーションを構築します。例えば、Atomsは、ボタンやテキスト、インプットなど、これ以上分割できない最小単位のUIを指します。

出典: Atomic Design (opens new window)
Moleculesは、Atomsを組み合わせて作るUIになります。例えば、インプットとボタンを組み合わせた検索ボックスなどが当てはまります。Organismsは、さらにAtomsとMoleculesを組み合わせて、単体で機能するようなUIになります。例えば、ヘッダーやフッターなどが当てはまります。
このようにコンポーネントを細かく分割することで、コンポーネント一つ一つの責務を明確にし、再利用性を高めることができます。しかし、Atomic Designにも課題はあり、実際に運用すると、コンポーネントの分類で悩むことが度々あります。MoleculesとOrganismsどちらに分けていいか迷ったり、コンポーネントの粒度だけで判断して、汎用性の低いコンポーネントがAtomsに量産されて見通しが悪くなったりなど、いくつかの課題を抱えることもあります。例えば、特定のページでしか使われないボタンがAtomsに量産されてしまうなどのケースです。
src/components/atoms
├── Button.tsx
├── AboutButton.tsx // Aboutページでしか使われていない
├── BlogButton.tsx // Blogページでしか使われていない
├── ContactButton.tsx // Contactページでしか使われていない
デザインチームとの連携で未然に防ぐこともできますが、規模が大きくなってくると見落とされがちになってしまうこともあるでしょう。こうなると、依存関係や影響範囲が分かりづらくなり、汎用性が失われてしまいます。はじめから汎用的なコンポーネントを設計できるのが理想ですが、それが難しい場合は、まずは影響範囲を絞って限定的にコンポーネントを分類する方が分かりやすくなります。
例えば、上記の例だと、pagesフォルダにそれぞれのボタンコンポーネントを定義しておきます。
src/pages
├── Home
│ ├── Component.tsx
│ ├── Container.tsx
│ └── index.ts
├── About
│ ├── Component.tsx
│ ├── Container.tsx
│ ├── AboutButton.tsx // Aboutページでしか使われていない
│ └── index.ts
├── Blog
│ ├── Component.tsx
│ ├── Container.tsx
│ ├── BlogButton.tsx // Blogページでしか使われていない
│ └── index.ts
├── Contact
│ ├── Component.tsx
│ ├── Container.tsx
│ ├── ContactButton.tsx // Contactページでしか使われていない
│ └── index.ts
このような配置にすることでコンポーネントを限定的にし、一目で影響範囲を把握することができます。そして、AtomsやMoleculesには汎用的に使われるコンポーネントだけを定義し、再利用性を保つことができます。これは単純な例ですが、実際の現場では複雑なケースが多くなってくるでしょう。そのため、まずは限定的にコンポーネントを分類し、汎用的に使う必要性が出てきてはじめて共通化するのがいいでしょう。
また、コンポーネントの粒度についても、TemplateやPagesを使うメリットを感じられなかったら、Atoms、Molecules、Organismだけを使うパターンでも問題ないと思います。
src/components
├── atoms
│ ├── Avatar
│ ├── Badge
│ ├── Box
│ ├── Button
│ ├── Checkbox
│ ├── Collapse
│ ├── Icon
...
├── molecules
│ ├── AttachmentBox
│ ├── Chips
│ ├── Toast
│ ├── Tooltip
...
├── organisms
│ ├── Accordion
│ ├── Carousel
│ ├── DatePicker
│ ├── Drawer
│ ├── Editor
...
重要なことは、適切にコンポーネントを分類し、再利用性を高めることなので、柔軟に対応していくことが必要となります。
TIP
Atomic Designについては、コンポーネントの章で詳しく解説しています。
さらに、デザインシステム (opens new window)を導入すれば、デザインを統一できUIに一貫性を保つことができます。例えば、GoogleがデザインしているMaterial Designでは、次のようなボタンUIが定義されています。

出典: Material Design (opens new window)
例えば、このようなボタンを<Button></Button>コンポーネントとして作成しておけば、アプリケーション全体で共通のボタンを使うことができるでしょう。
出典: Material Design (opens new window)
また、この<Button></Button>コンポーネントは、ボタンのUIを表示するという責務だけを持ちます。そのため、単体テストもボタンの振る舞いや見た目だけに注力できます。仮に、ボタンのデザインを変えたくなったとしても、アプリケーション全体で<Button></Button>コンポーネントだけを使用しているので、一箇所の変更だけで済みます。このように責務を明確化することで、コンポーネントの汎用性を維持し、再利用しやすいコンポーネントを設計することができます。
デザインシステムの導入が難しい場合は、Chakra UI (opens new window)などのUIライブラリを導入すれば、デザインシステムをベースとした汎用コンポーネントを使用することができます。ボタンや、タブ、メニューなど基本的なUIコンポーネントが用意されています。
出典: Chakra UI (opens new window)
UIライブラリを使うときもプロジェクト内で<Button></Button>などのコンポーネントを作成しラップしておくと、メンテナンス性が高まります。例えば、ボタンコンポーネントなら次のようにラップします。
import {
Button as ChakraButton,
ButtonProps as ChakraButtonProps,
forwardRef,
} from '@chakra-ui/react'
import React from 'react'
type Props = ChakraButtonProps
export const Button: React.FC<Props> = forwardRef((props, ref) => {
return (
<ChakraButton ref={ref} {...props} />
)
})
ラップしておく理由としては、以下の通りです。
- カスタムがしやすくなる
- UIライブラリのバージョンアップに対応しやすくなる
カスタムのスタイルを当てたいときは、このコンポーネントに対して変更を加えるだけで済みます。例えば、lightというpropsを定義して、そのスタイルを当てる際は次のように書くことができます。
import {
Button as ChakraButton,
ButtonProps as ChakraButtonProps,
forwardRef,
} from '@chakra-ui/react'
import React from 'react'
type Props = ChakraButtonProps & {
light?: boolean
}
export const Button: React.FC<Props> = forwardRef((props, ref) => {
const { light, ...rest } = props
const style = {
...(light ? lightStyle : {})
}
return (
<ChakraButton ref={ref} {...style} {...rest} />
)
})
また、UIライブラリのバージョンアップをしてBreaking Changeがあったとしても、変更範囲をこのコンポーネントだけに抑えることができます。アプリケーション全体でimport { Button } from '@chakra-ui/react'を使用していると、全てのコンポーネントに適用しなければなりません。しかし、一箇所にまとめておけば最小限の変更で済むため、メンテナンス性が高くなります。
import {
Button as ChakraButton,
ButtonProps as ChakraButtonProps,
forwardRef,
} from '@chakra-ui/react'
import React from 'react'
// 例: colorがfontColorという命名に変わった
type Props = ChakraButtonProps & {
color?: ChakraButtonProps['fontColor']
}
export const Button: React.FC<Props> = forwardRef((props, ref) => {
// 既存で使われているcolorを維持しつつ、 `fontColor`に変更する
const { color, ...rest } = props
return (
<ChakraButton ref={ref} fontColor={color} {...rest} />
)
})
# テストで動作を担保
大規模なリファクタリングや機能追加などでコードを大幅に変更しなければいけないときに最も懸念されるのがリグレッションバグです。変更しやすい仕組みを作るためには、変更を検知しやすい仕組みを整えることが必要です。変更を検知しやすい仕組みとして最も有効なのが、テストを書くことです。単体テストまたは、統合テストで動作を保証しておくことで、バグを未然に防ぐことができます。
一般的にテストの役割は次のようなものがあります。
- 機能を担保する
- コードの品質を保つ
- 開発効率を上げる
フロントエンドのテストは、コンポーネントに対して行い、機能を担保します。その際、ユーザーが使うときと同じようにテストすることが望まれます。例えば、ユーザーがボタンを押下して「Hello」という文字列が表示されるアプリケーションを考えてみましょう。
import React, { useState } from 'react';
export function App(props) {
const [text, setText] = useState('')
const handleClick = () => {
setText("Hello")
}
return (
<div>
<button onClick={handleClick}>button</button>
<div>{text}</div>
</div>
);
}
このコンポーネントのテストを書く際は、ボタンを押下して「Hello」という文字列が画面に表示されたかを担保する必要があります。コンポーネントのtextがどう変わったかについては関与する必要はありません。仮に、内部のtextに対してテストをしていたとすると、次のような処理が追加された場合、正しくない挙動にも関わらず、テストが通ってしまいます。
import React, { useState } from 'react';
export function App(props) {
const [text, setText] = useState('')
const [text2, setText2] = useState('')
const handleClick = () => {
setText("Hello")
setText2("Hey")
}
return (
<div>
<button onClick={handleClick}>button</button>
<div>{text}{text2}</div>
</div>
);
}
expect(text).toBe("Hello") // textはHelloのままだからテストは通る
実際の表示は「HelloHey」にも関わらず、テストが通ってしまい、機能を担保することができていません。動作の担保をするためには、内部の挙動がどうであれ、常にユーザーと同じ結果になるようにテストすることが求められます。 Reactの場合は、Jestやreact-testing-library (opens new window)などを使うことが多いでしょう。react-testing-libraryは、基本的にモックを少なくして実動作と同じようにテストすることを推奨 (opens new window)しています。継続的なリファクタリングには、変更に強い土台が必要です。そのためには、このような動作を担保できる仕組みが必要となります。
テストの役割は、機能の担保以外にも、コードの品質を保つ役割があります。テストが書きづらいコードは、依存するコンテキストが多い傾向にあります。依存関係が多いとコードの見通しが悪くなります。その結果、メンテナンスコストが高くなります。テストを書く環境を整えるには、テストしやすい設計にする必要があります。テストしやすい設計にすると、依存関係が整理され、おのずとシンプルなコードになります。シンプルなコードを保つことで、継続的なリファクタリングがしやすい環境になります。
テストのメリットのみ見てきましたが、デメリットにも注意を払うべきでしょう。 テストのデメリットは、そのメンテナンスコストです。テストの数が多いとその分、改修コストも高くなります。テスト実行時間の増加、CIだけテストが通らないなど、様々なケースが発生しがちです。
注意する点としては、カバレッジを100%目指さなくていいということです。カバレッジはあくまで現状を把握するための指標で、目標にすべきではありません。アプリケーションの主要な機能が担保されていれば、それで十分です。逆に、低いカバー率の場合は、テストを増やす必要があるでしょう。テストが多すぎるとメンテナンスコストも上がってしまうため、バランスをとる (opens new window)ことが重要となります。
そして、このアプリケーションの主要な動作を担保するには、統合テストが有効です。統合テストを書く際は、モックはなるべく使わないで実動作と同じように書くことが望まれます。このモックを使うか使わないかでは、ロンドン派(Mockist)とデトロイト派(Classical)という考え方があります。
ロンドン派(Mockist)はテスト対象の依存関係をモックに置き換えて、コードを検証するアプローチです。依存関係をモックするため、容易に、そして、高速にテストを実行できるというメリットがあります。デトロイト派(Classical)は、なるべく依存関係をモックしないで動作に対して検証するアプローチです。
どちらのパターンにするかは個人の裁量になりますが、フロントエンドテストの場合は、デトロイト派(Classical)の方が有効的でしょう。なぜなら、上記で示した通り、ユーザーと同じ振る舞いをテストした方が機能の担保がしやすいためです。フロントエンドの依存関係で大きいものは、API通信です。統合テストに実際のAPIを用いることは難しいので、擬似的に再現する必要があります。MSW (opens new window)というライブラリを導入すれば、実際に通信を発生させてレスポンスを受け取ることができます。このようなツールを使うことで、なるべく実動作と同じような環境でテストすることが重要となります。
# Visual Regression TestingでUIの担保
上記で紹介したテストは動作を担保するための機能テストですが、フロントエンドでは、UI/UXに対するテストも必要となります。近年、コンポーネントの見た目をテストする手法として、Visual Regression Testingというテストが採用されるようになりました。
Visual Regression Testingとは、コンポーネントのレンダリング結果を画像として保存し、画像の差分を比較することで、UIの変更を検知するためのテストです。コンポーネントのレンダリング結果を比較するものでは、JestのSnapshot Testing (opens new window)が使われていましたが、HTMLを目視で確認するだけなので、見た目のテストととしては不十分でした。Visual Regression Testingでは、実際に画像の比較を見ることができるので、意図した変更か、意図しない変更かを判断しやすくなっています。
例えば、Chromatic (opens new window)というサービスでは、次のように、変更前の画像と変更後の画像を比較して見ることができます。
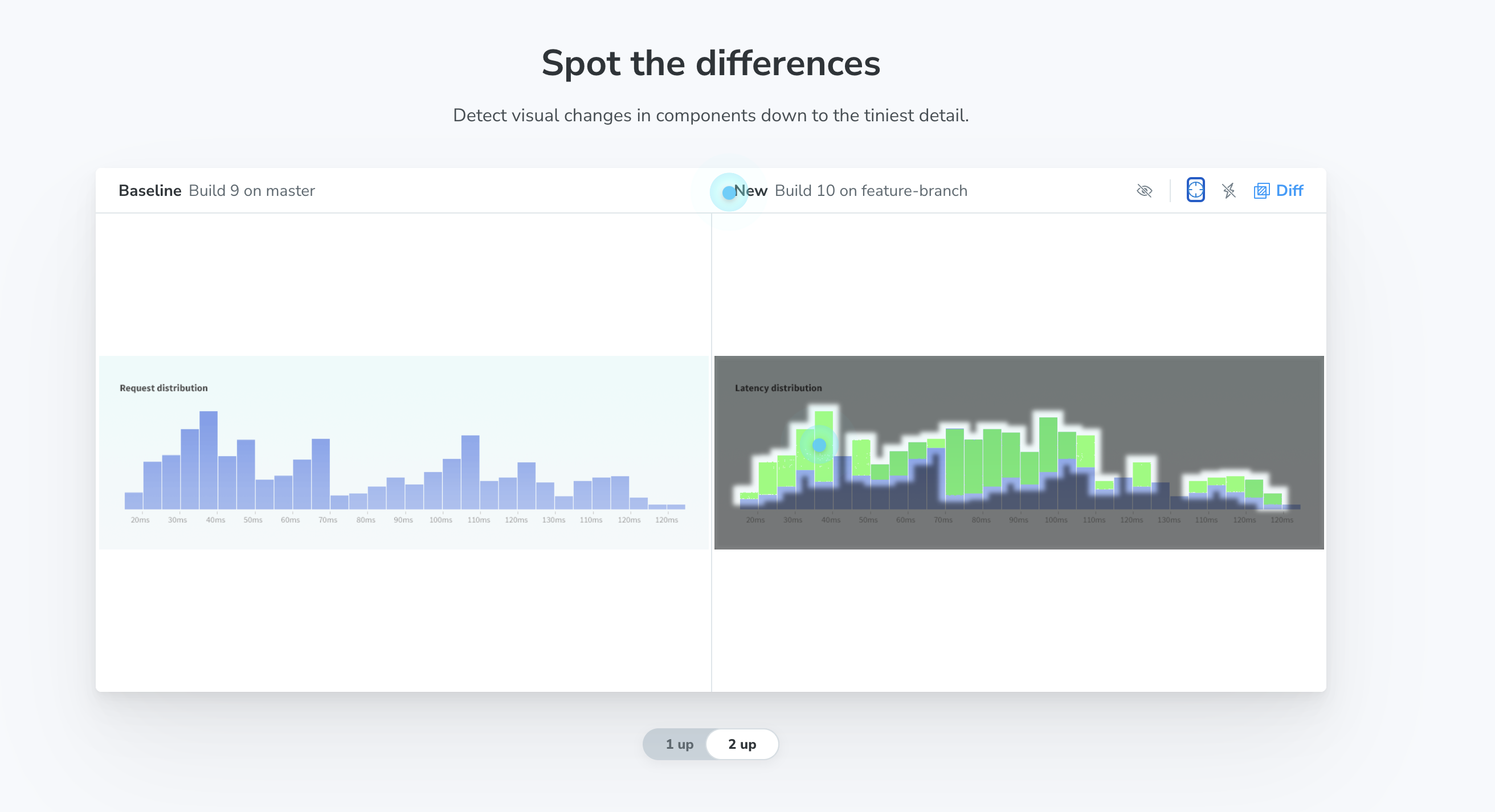
CIと連携しておけば、コンポーネントを更新する度に、UIの変更を検知してくれます。大規模なリファクタリングの場合、UIの変更は人の目で見る他ありませんが、Visual Regression Testingを導入すれば、自動で機械的にテストすることができます。UIライブラリなどのバージョンアップで、気づかないうちに見た目が変わっていた、などのケースもあると思います。Visual Regression Testingを積極的に活用することで、そのような細かい変化を検知することができます。
Visual Regression Testingのツールはいくつかあります。
Chromaticは、UIのチェックやレビュー環境を提供しているSaaSです。有料になりますが、CIとの連携もスムーズにできます。無料で運用したい場合は、reg-suitで同様なことが可能です。
# TypeScriptでデータの不整合を検知
近年、フロントエンド開発でTypeScriptが採用されることが多くなってきました。TypeScriptはReactなどのUIフレームワークとも親和性が高く、データを安全に扱うことができます。CIに組み入れることで、型エラーを自動で検知し、バグを未然に防ぐことが可能です。TypeScriptを活用することで、データの不整合やバグの回避が可能となり、リファクタリングの心理的負荷も軽減することができます。
フロントエンドでよく発生する課題は、APIのデータとの整合性です。通常、APIからのデータに型をつける場合は、自身で定義する必要があります。例えば、Userデータを取得する場合は次のようになります。
export type User = {
id: number
name: string
email: string
age: number
phone: number
}
しかし、APIの仕様が変わったタイミングで型の修正もしなければならず、意図しないところで不整合を起こす可能性があります。これはフロントエンドの共通の課題となっており、いくつかの対策が取られています。
例えば、GraphQLを使ったプロジェクトでは、GraphQL Code Generator (opens new window)というツールを使うと、自動的にGraphQLのスキーマからTypeScriptの型定義を生成してくれます。クエリやパラメータの型が定義されるので、APIの変更に対して自動的に適用してくれます。また、Restful APIで実装しているプロジェクトなら、Open APIのopenapi-typescript (opens new window)を導入すれば、同様に、自動的にTypeScriptの型を生成することができます。
試しに、次のようなクエリファイルをGraphQL Code Generatorで生成してみましょう。
type Query {
user(id: ID!): User
}
type User implements Node {
id: ID!
username: String!
email: String!
}
このクエリファイルをもとに、次のようなTypeScriptファイルが生成されます。
export type User = Node & {
__typename?: 'User';
id: Scalars['ID'];
username: Scalars['String'];
email: Scalars['String'];
};
また、typescript-react-query (opens new window)というプラグインを使用すると、クエリを取得するカスタムHooksを生成することもできるので、APIとの連携を自動化することも可能です。
export const useFindUserQuery = <
TData = FindUserQuery,
TError = unknown
>(
dataSource: { endpoint: string, fetchParams?: RequestInit },
variables: FindUserQueryVariables,
options?: UseQueryOptions<FindUserQuery, TError, TData>
) =>
useQuery<FindUserQuery, TError, TData>(
['findUser', variables],
fetcher<FindUserQuery, FindUserQueryVariables>(dataSource.endpoint, dataSource.fetchParams || {}, FindUserDocument, variables),
options
);
このように、データの取得やコンポーネントのPropsなどをTypeScriptで型定義しておくことで、データの不整合を未然に防ぐことができます。学習コストはありますが、型チェックやエディターでの自動補完など、TypeScriptの導入はメリットが大きいので積極的に活用した方がいいでしょう。
# バグを検知
アプリケーション開発をしている以上、バグは必ず発生してしまいます。 上記のようなテストや型検知で、バグの数を減らすことはできても、完全に無くすことは無理でしょう。そのため、バグをいち早く検知し、修正するための仕組みが必要となります。
フロントエンドでバグを検知するためのサービスは、Sentry (opens new window)やdatadog (opens new window)などがあります。JavaScript用のSDKや、React、Vue.jsなどのフレームワークにも対応しているため、比較的簡単に導入することができます。このようなエラー監視サービスを活用して、エラーを検知する仕組みを整えておきましょう。
Sentryでは、ソースマップやバージョン管理もできるため、いつのリリースで発生したバグかを特定しやすくなっています。また、Session Replay (opens new window)という機能では、実際にユーザが操作してエラーまでに至った経緯を動画で見ることができます。
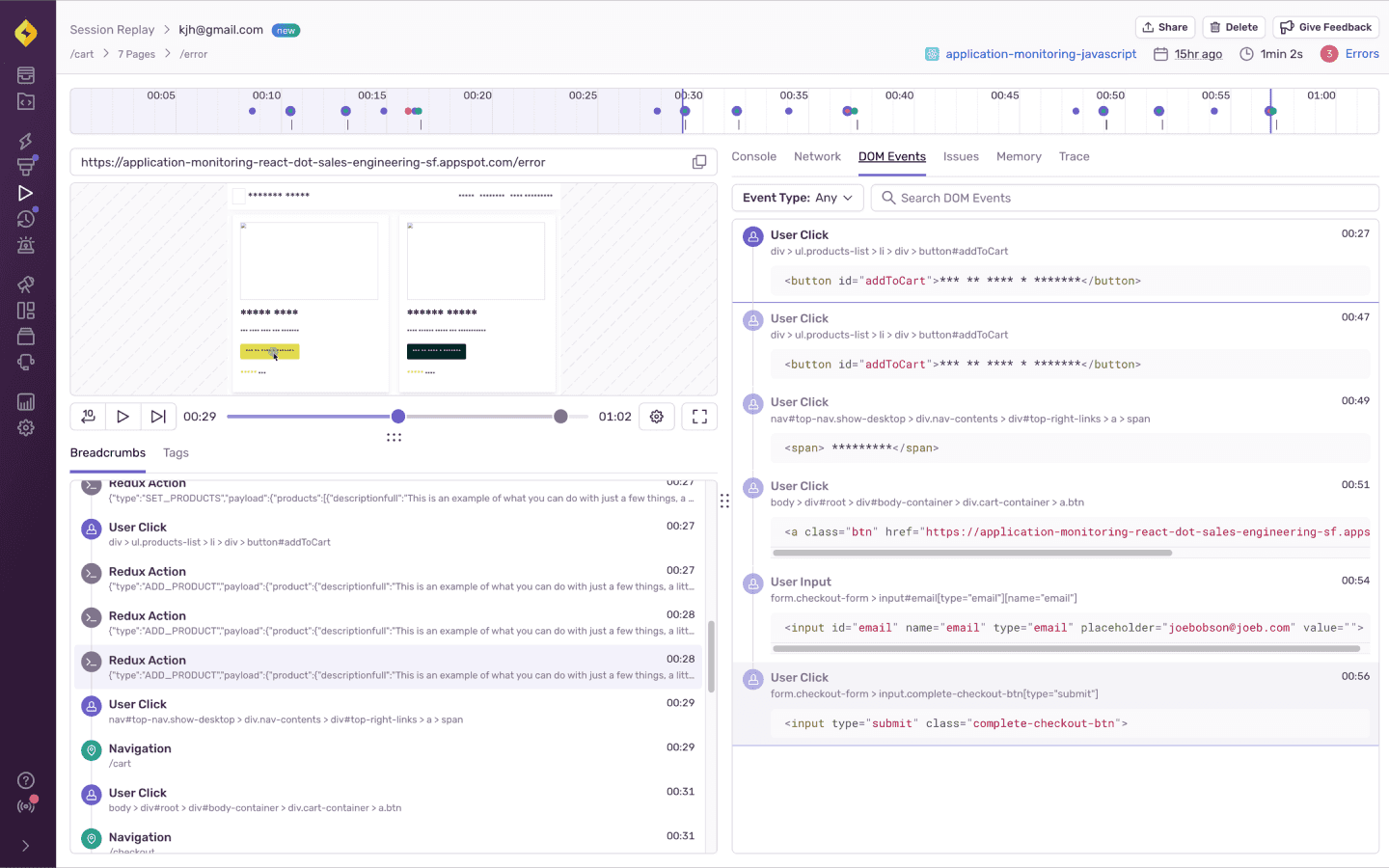
実際に動画を撮っているわけではありませんが、DOMのスナップショットを保存して、そこから再現しています。そのため、発生したときのDOMやコンソールも見ることができます。
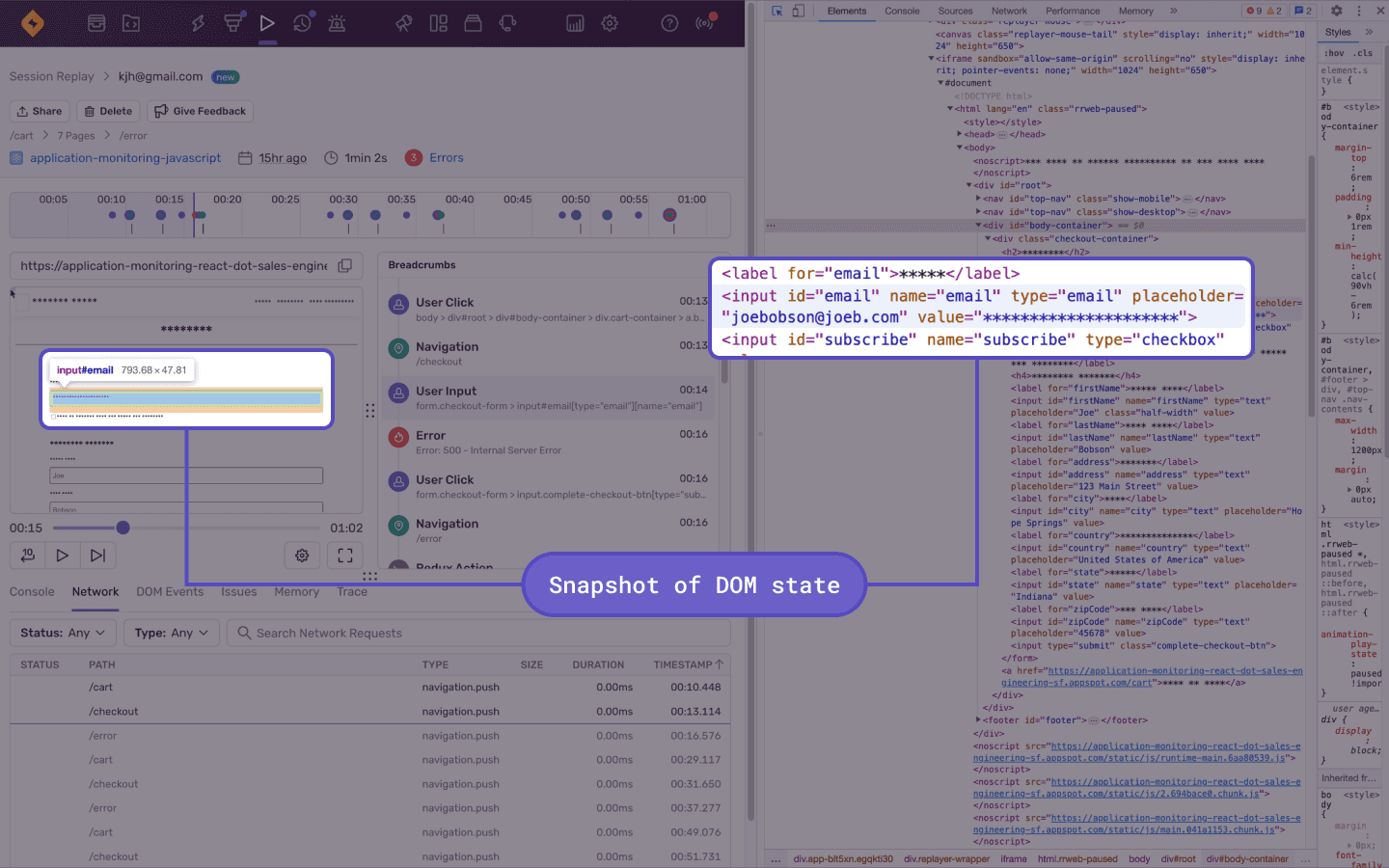
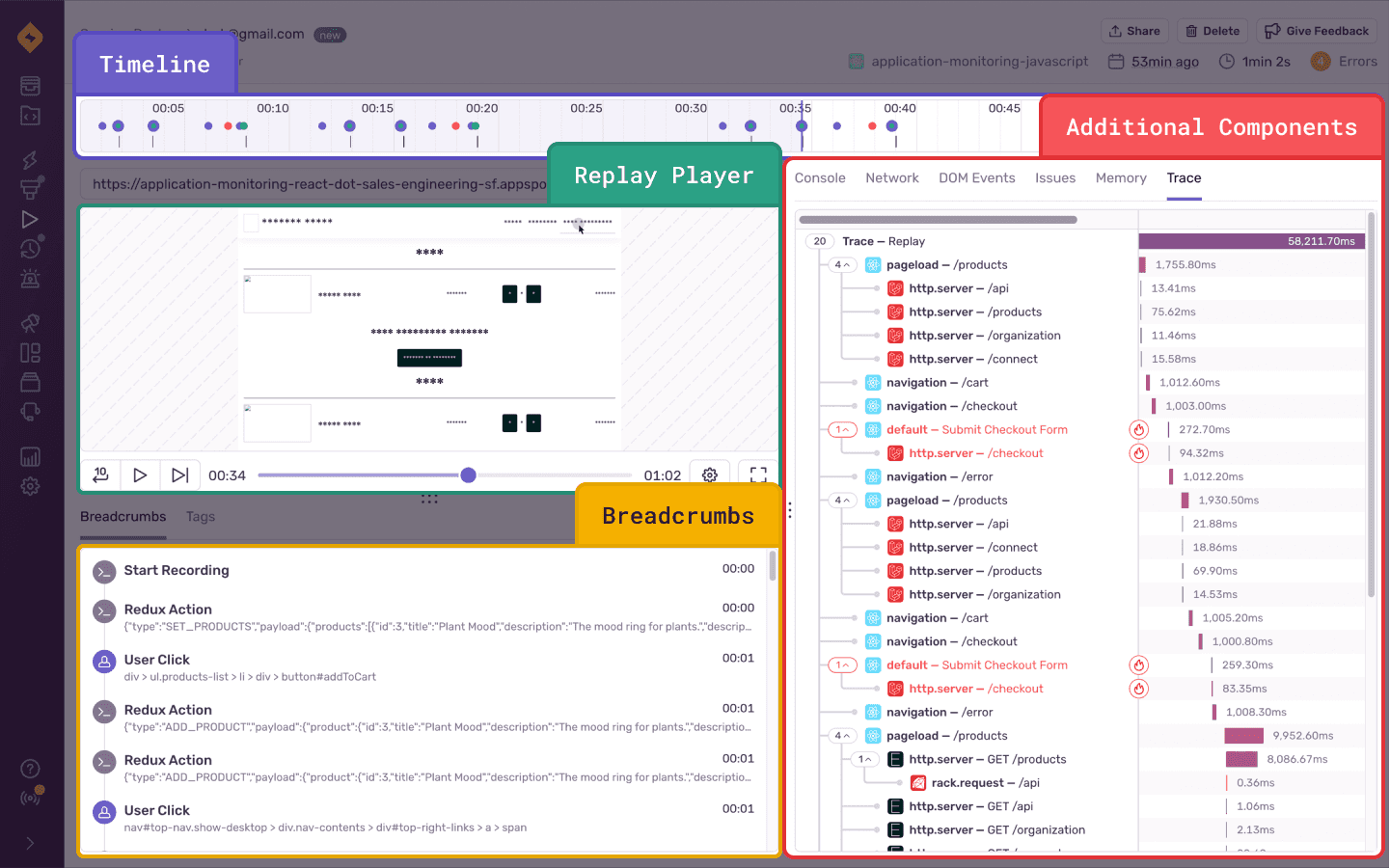
その他にも、パフォーマンスやコードカバレッジ (opens new window)のモニタリングなどのサポートもしています。Slackと連携することでリアルタイムにエラー状況を把握することもできます。バグを無くすことは難しい課題ですが、バグが起きることを前提にシステムを運用していくことが重要となります。